
What is one of the important factor to a project’s success? If you are a QA then your answer would be Testing, right ? but, what are the important things that makes software testing good ? Answer may vary from person to person based on their experience but I think there is one thing that most of us can relate to, that is good Test Data.

This simple logic implies that test data is an important factor for project’s success. Everyone related to software industry would agree on this. So if test data preparation is an important, then why do we seldom ignore it until encounter a problem?
For more information about having production alike data in test environments checkout Thoughtorks technology radar blip
Testing is not going to be an easy task even though QA’s have become more informed and effective. They will always rely on good test data in order to provide satisfactory software quality.
Below are some common test data problems that can be encountered at the time of software testing

Data aggregation/Batch run:
Having prod equivalent data volume in lower environment will result
- longer batch/aggregation processing time.
- more data storage space
- uncertainty of corner/edge cases or any specific testing scenario requirement.
- querying data for validation will consume significant time
- automated test might timeout or take unappreciated longer time due to time consuming run time query execution.
Data complexity:
Production equivalent Test data is not simple and straightforward
- Sometimes the test data is not simple and straightforward. Testers may need to learn new terminologies, patterns, standards in order to understand the flow/use of data.
- Data might be entangled with multiple sources , tables or schemas , etc.
- Some scenarios may not even be possible to test in the test environment. In this instance, testers may need to devote a good amount of time to * understand the scenarios and come up with a new and efficient way to prepare the data.
Data accessibility:
Test Data access, dependencies on multiple teams consuming it
- Access to data manipulation might be restricted since multiple people, teams can be using it and the tester will not always be able to manipulate the data, as required.
- QA’s have to manipulate the data in the test database before figuring out what specifically needed to be changed. Significant amount of time is spent on * learning the databases names, table relations, column data, and their correspondence to the application, their properties and constraints.
Inefficient processes:
Another challenge that Testers may face is dealing with inefficient processes. By challenging the client’s current process and introducing a new, more * efficient model, team should be able to produce a quicker way for testers to fill in accurate data.
Lets talk about challenges we faced in our project
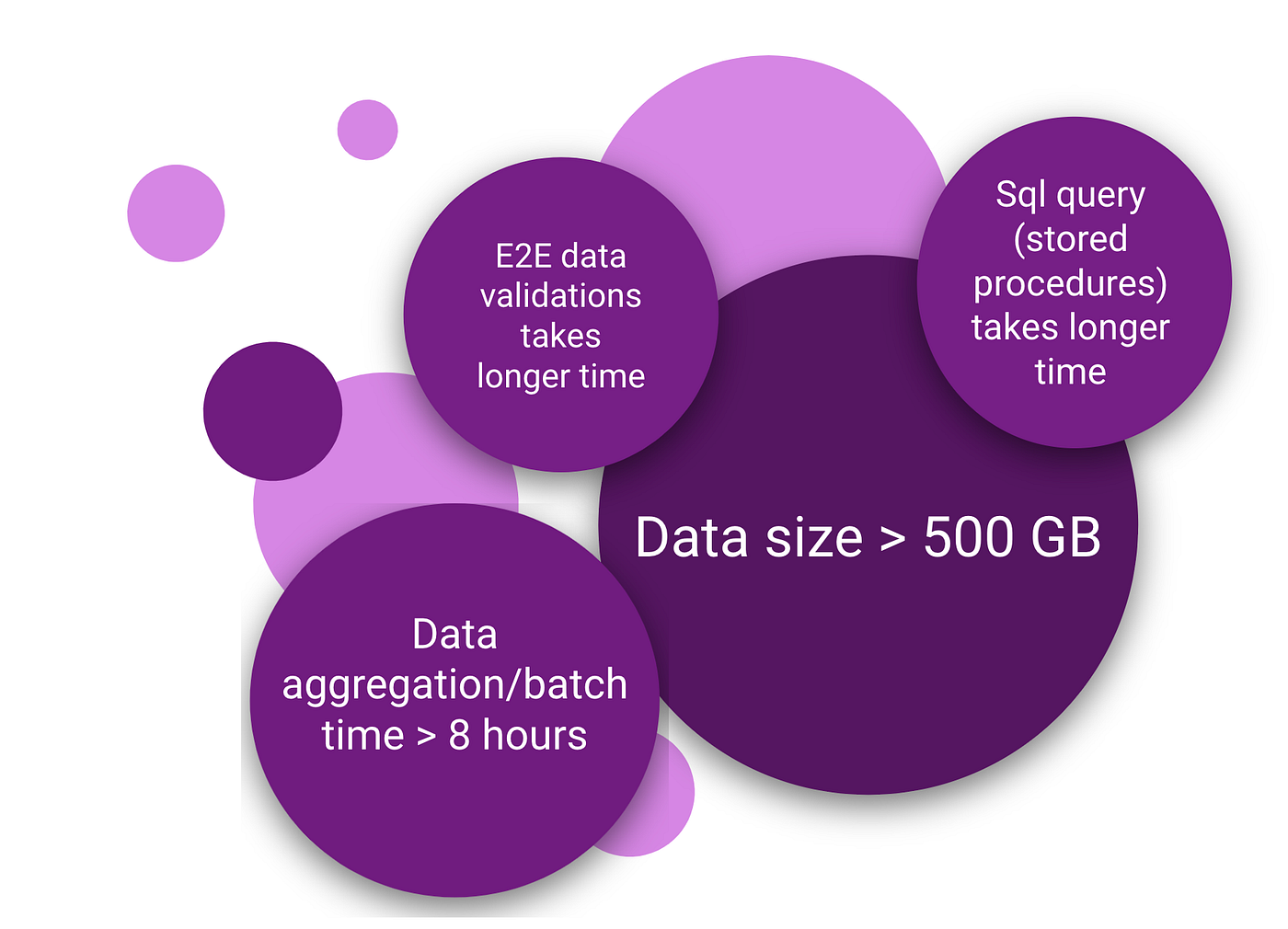
- prod equivalent data volume on lower environments
- data size > 500 gb (> 40 interrelated tables having millions of rows)
- batch processing takes longer than 8 hours, if any thing go wrong it takes a complete day to take and act on a feedback.
- cloud data storage cost
- multiple teams are consuming the environment and hence ad hoc changes in data will disrupt rest of the teams and activities to cover edge cases or any specific testing scenarios.
- views and procedures used to validate the final data outcome on UI takes extra maintenance activity over sprints and longer query execution time (millions of rows has complex joins with multiple tables)
Solution

- our first thought was to reduce the execution time for → aggregation/batch processing (faster feedback) → quick sql query execution (faster manual and automated test feedback)
- client was migrating to cloud so data store space cost was also being considered
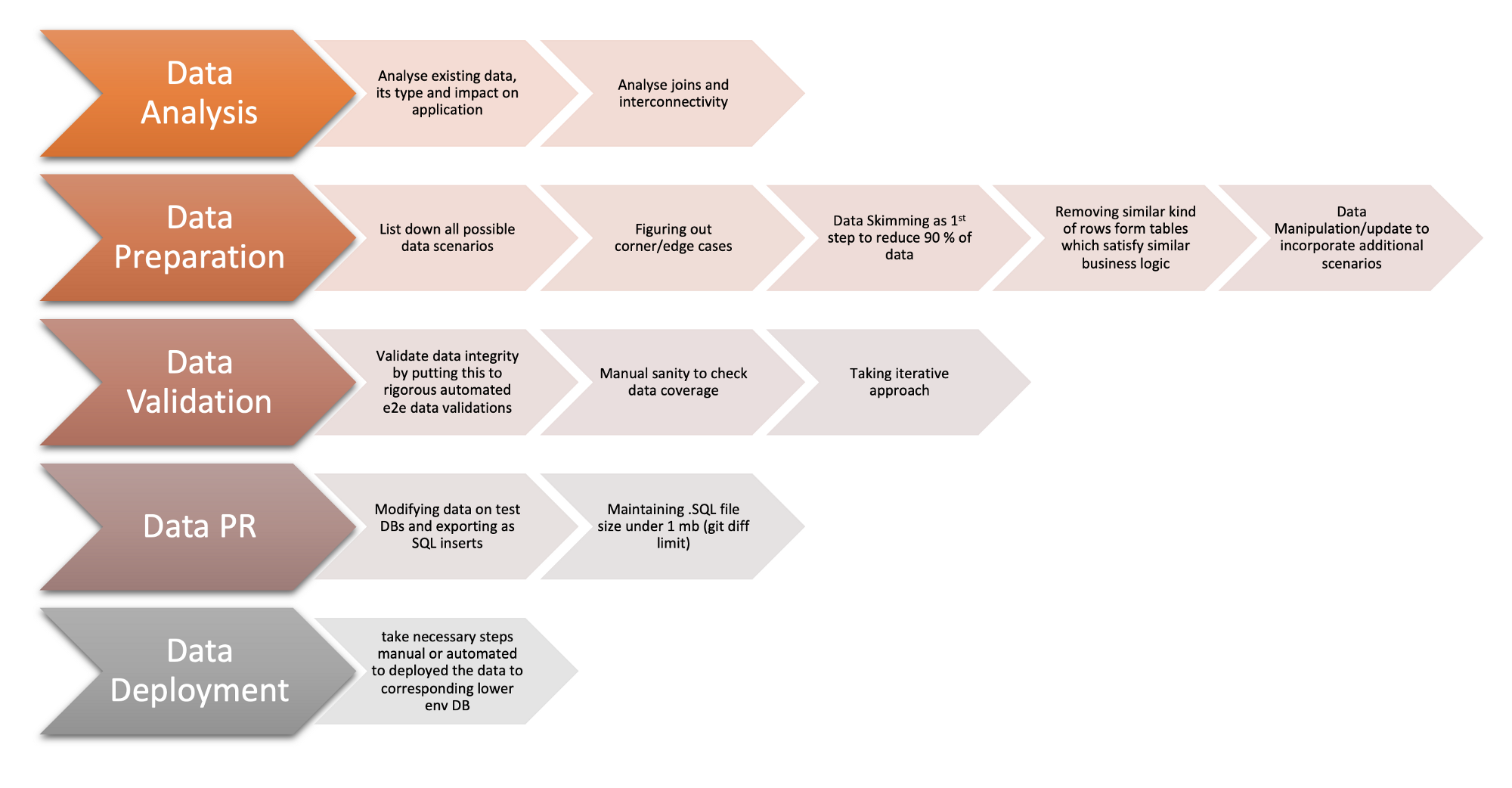
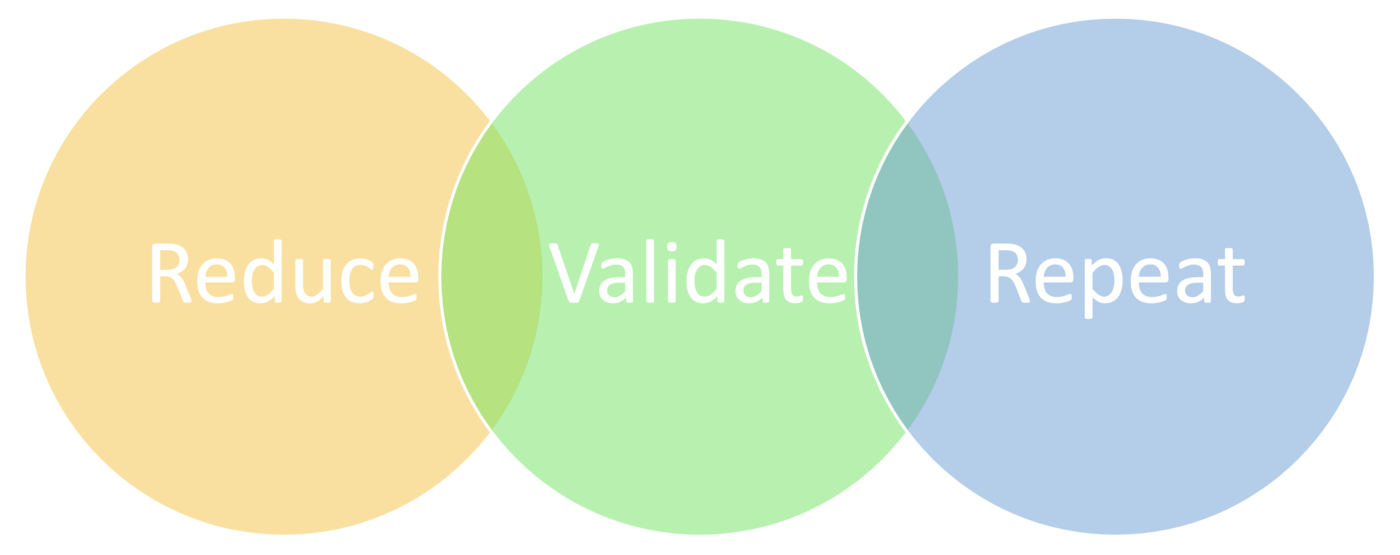
Taking an Iterative approach would make data reduction process a little more easier. It will also help us build confidence on reduced test data reliability to suffice QA and automation testing needs. Below are the Major steps we took in order to start the data reduction.
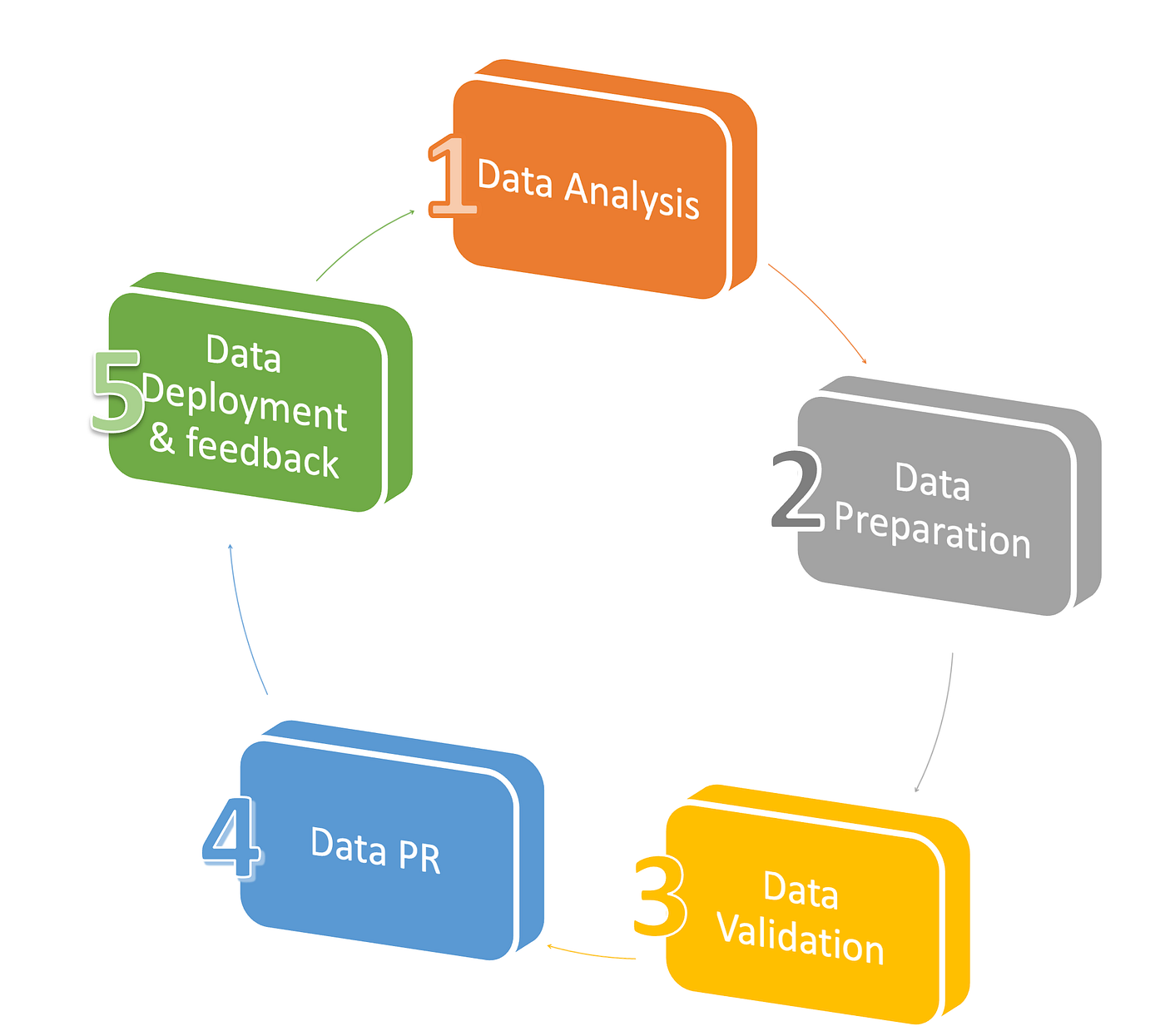
step 1 → data analysis
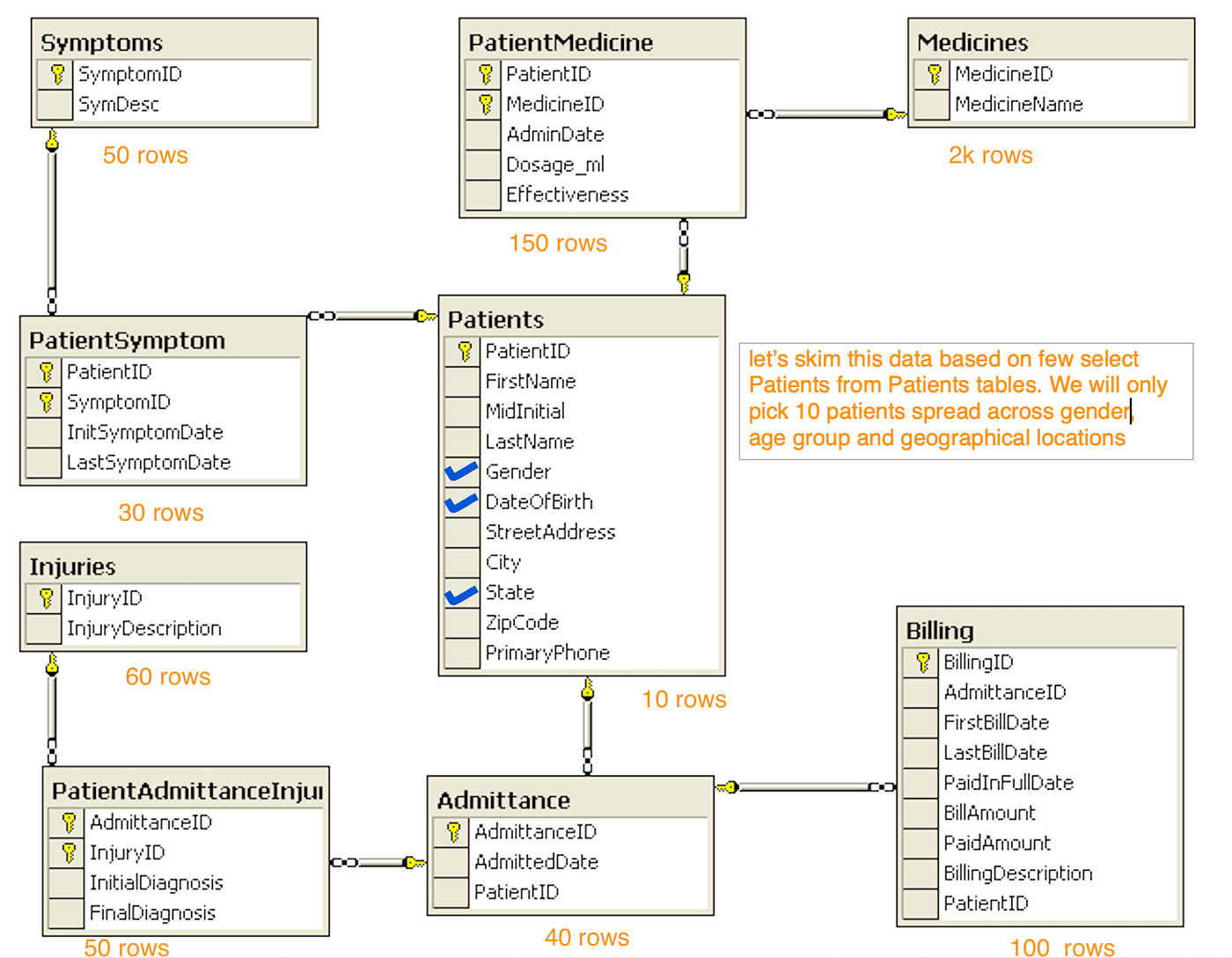
- Let’s consider below patient health Management DB system. Observe the data size (rows count are in millions). Do we really need millions of Patient records in order to validate this system ?

- Analyze existing data, its type and impact on application.
- Analyze joins and inter connectivity
- Evaluate estimated reduced target size of tables either in Kbs/Mbs or in rows count
- Also analyze source control system limitation to track the changes (for example git has 1 mb/20000 lines data limit in order for it to show the diff)
step 2 → data preparation
- List down all possible data scenarios.
- Figure out corner/edge cases
- List down Data Skimming data chain (refer Flow 2 diagram). Identifying ~10 patients belongs to different gender , age group and geographical location will suffice the testing needs.
- Follow the existing data chain for these patients and understand how data for these patients impacts the application.
- Also , skim down other tables based on Identified patients
- Alternatively TABLESAMPLE can also be used to pick random data from tables (refer Flow 3 diagram)
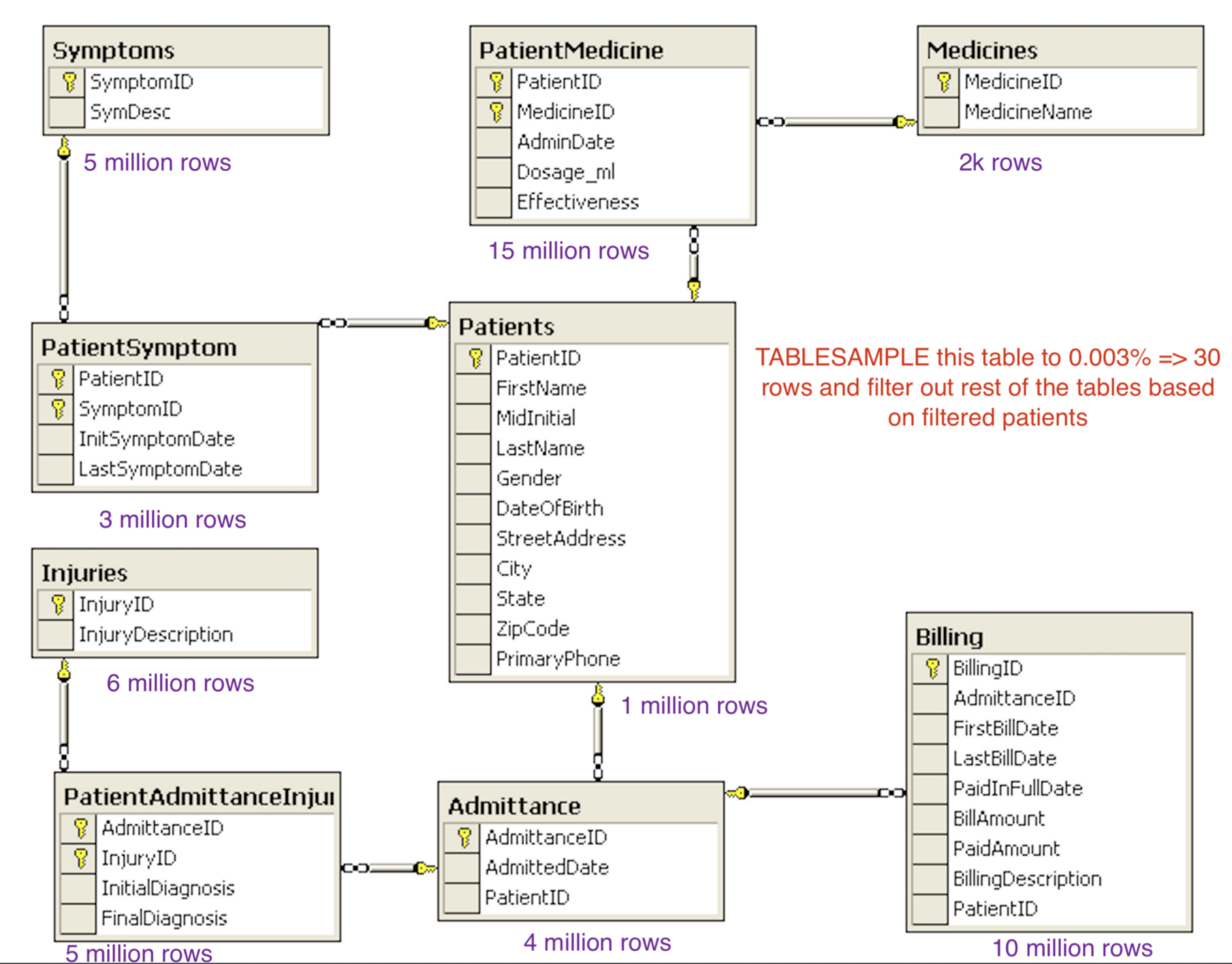
- Be mindful about the join keys and make sure to update skimmed/reduced tables with proper overlap of data from interconnected tables
- Make note of similar kind of rows form tables which satisfy similar business logic (we might have to remove/update this data either to further reduce the table size or accommodate corner/edge cases )
Step 3 → data validation
- Take data dump to test DB where data experiments/trials can be performed and validated
- Spin up local/docker application setup and connect it with test DB
- Implement step 2 analysis and update Test DB
- Perform manual sanity to validated data coverage and edge cases
- Also execute Automated Test to validate data integrity and compatibility
- Be patient and take iterative approach — This step is one of the most time consuming part of data reduction.
- Be mind full about the source control tracking limit
Step 4 → data PR
- After having satisfactory result form data validation step we are good to go for next step, that is following data update review and deployment process.
- We used git to track the changes , and as analyzed in step one (data analysis) , git has some limit to track the changes (1 mb or 20,000 rows
- Dump tables export as .SQL file having sql inserts statements
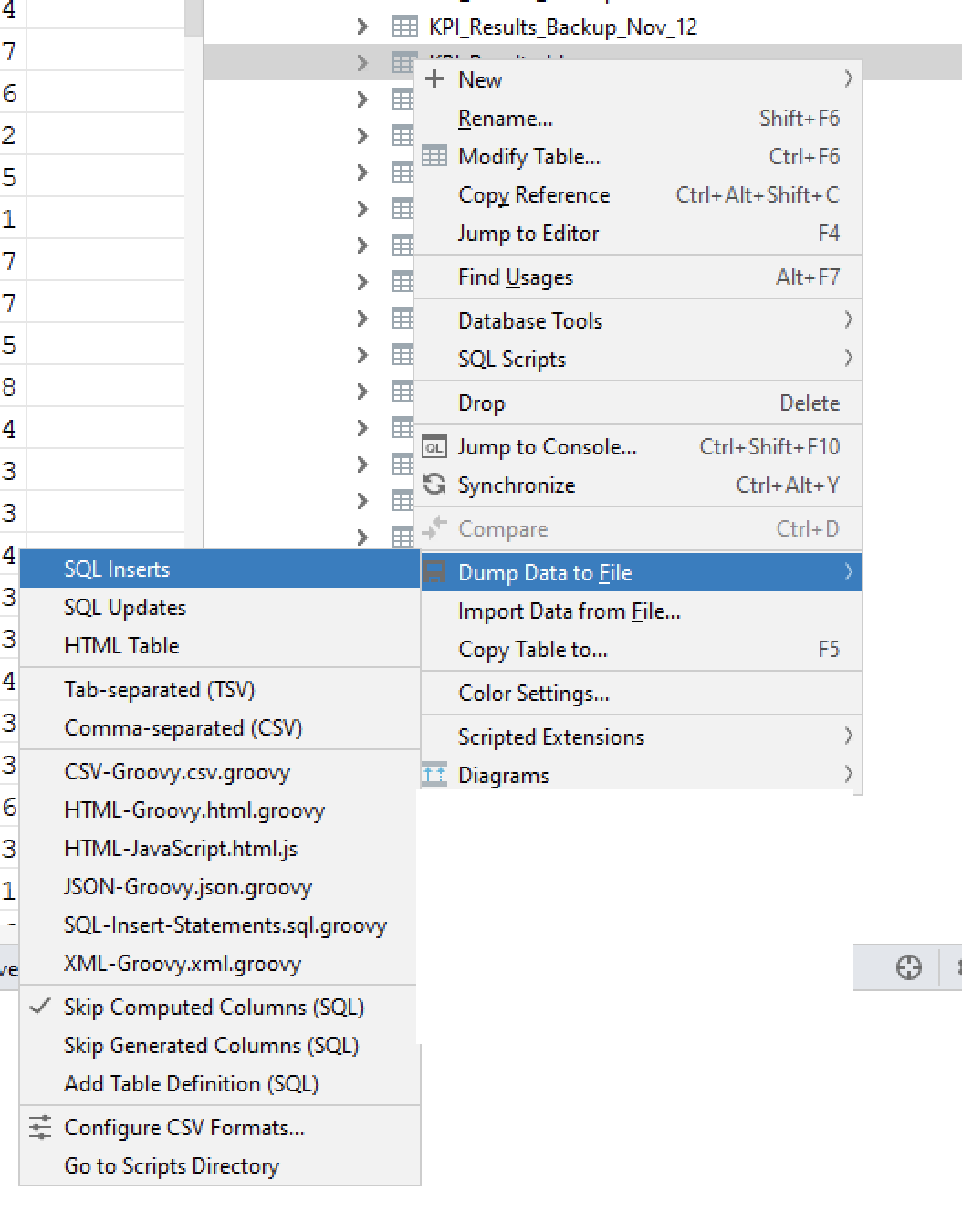
- Measure the file size it should be under an mb (git diff limit), if it exceeds then run below awk command to eliminate the repeated insert into statements in every line.
awk ‘BEGIN{match_count=0;} $0~/^INSERT.*VALUES \(/{match_count++;if (match_count%1000!=1) gsub(“INSER INTO .* VALUES \\(“, ”\(“, $0); if (match_count%1000!=0) gsub(“;$”, “,”, $0); print $0}’ input file.sql > output file.sql

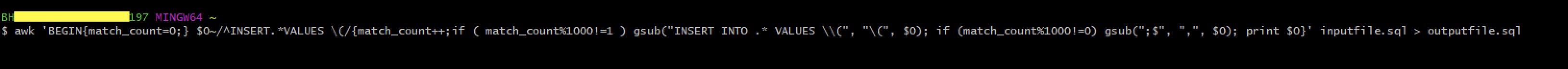

Observe the reduction in size before and after running the awk command utility
awk ‘BEGIN{match_count=0;} $0~/^INSERT.*VALUES \(/{match_count++;if (match_count%1000!=1) gsub(“INSER INTO .* VALUES \\(“, ”\(“, $0); if (match_count%1000!=0) gsub(“;$”, “,”, $0); print $0}’ QA_dbo_DDLEvents.sql > QA_dbo_DDLEvents_batched.sql

- Once you are satisfied with file raise the Data PR and ask for review and approvals from key stakeholders so that everyone is aware of your changes
Step 5 → data deployment
take necessary manual or automated steps to deploy the data (execute .sql files in db/tables) to populate desired tables in targeted lower environments
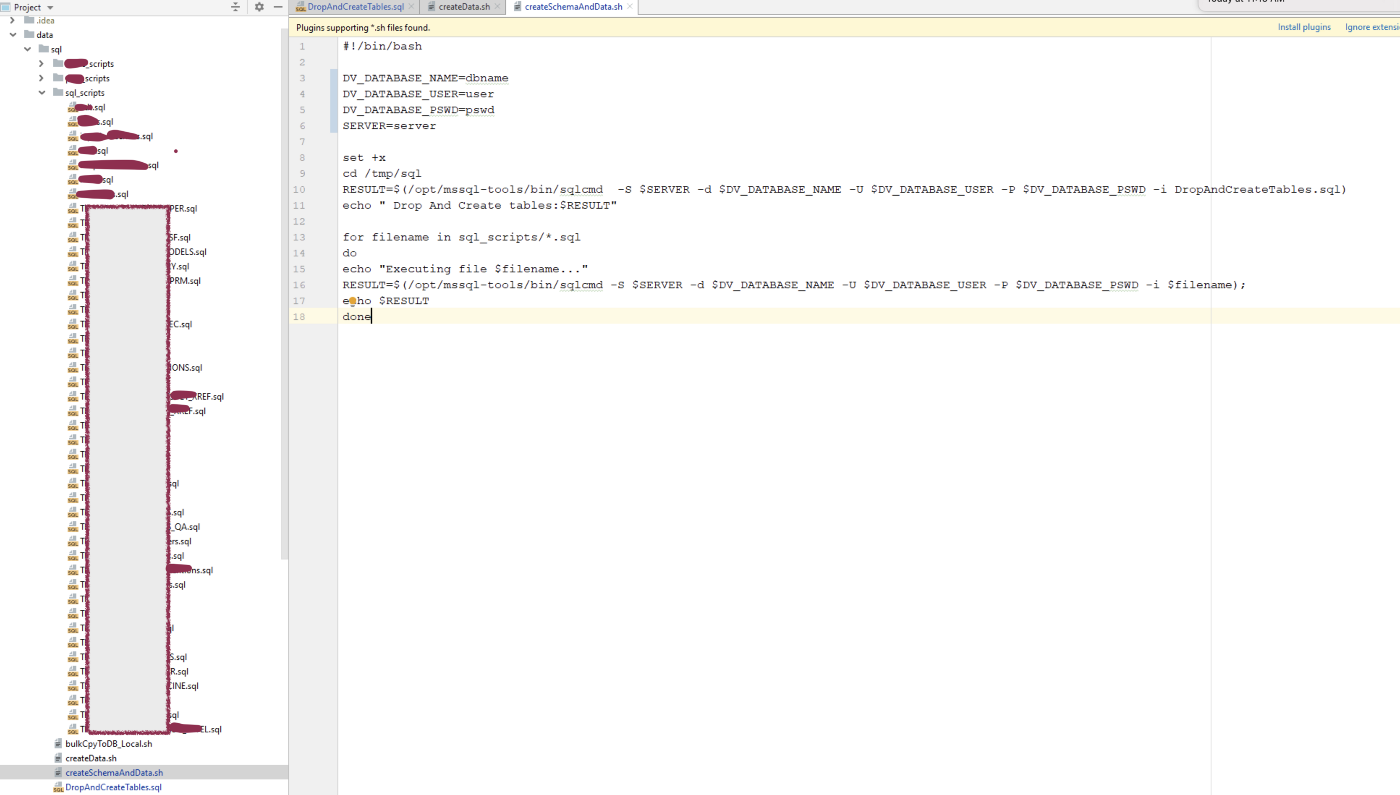
- createSchemaAndData.sh

- create DropAndCreateTable.sql to drop and recreate tables with required changes/updates
- Overall Data repository will look like this
Data reduction major steps
Data reduction Iteration
Final Outcome
Phenomenal amount of reduction in rows count now solves:

- current DB data size < 20 MB as compared to 500 GB (500000 MB)
- batch processing now takes less than 15 minutes as compared to earlier 8 hours, now we can work on several feedback in a day
- cloud data storage cost is drastically reduced for lower environments (Dev, QA, Training)
- multiple teams can now work seamlessly with this reduced data and reduction process since data change management system is built to track and deploy data with proper approvals with zero downtime.
- complex views and procedures now execute under a second as compared to several minutes
Steps for the future
Documenting: Document important sections of application details, procedures, queries, and glossaries into a quick fact sheet and training document that can be shared with the team. At times, full documentation may be overwhelming for newbies in the field. In that case, the quick fact sheet will serve as a way to answer common questions more efficiently.
Data management: As the application and testing teams grow bigger, it is best practice to formulate a way to manage the test data in an effective manner. Each industry standard will not be applicable to all cases, therefore, processes may need to be customized to meet project requirements. Look for gaps and ways to overcome them.
Test data preparation is a critical component of the entire preparation process and it is important to any quality assurance process. Adopting a good mix of forethought, creativity and best industry practices is the best way to avoid those ever-present challenges and create an efficient process.