The Paradox of choice - Automation tool selection
Finding the right tool for automation testing is crucial. Wrong selection causes rework, limits coverage, and burns trust when the suite flakes. Yet the market offers dozens of “best” frameworks — welcome to the paradox of choice.
People usually pick the most popular tool in a category or whatever they used last project. That can work. It can also mean critical compatibility issues two quarters later when IE support, mobile WebView, or CI budget were never weighted.
Choosing automation tools is critical. Do not treat it as a one-hour meeting with a Google search.
What should really matter
- Scalability — suite growth, parallel runs, CI minutes
- Browser / OS compatibility — what YOUR users actually use
- Ease of creating scripts — dev participation, not only QA heroes
- Maintainability — locators, page objects, versioning
- Reporting — debug failures fast; integrate with Jira/CI
- Price — licenses, cloud devices, engineer time (often the biggest line)
Add team skills and app stack — React Native favors different choices than a Java shop on Selenium Grid (mobile strategy goes deeper on device side).
A tale of two teams
Same category of tools. Different winners. That is the point.
Team A — cost-sensitive, polyglot, wide browser matrix
- Cost-sensitive client
- Team comfortable with many languages
- IE, Chrome, Firefox, Safari support required
- Responsive design
- Strict performance benchmarks
- Asynchronous backend systems
Pain if they pick wrong: Cloud browser minutes explode; async waits make flaky suites; IE-specific locators rot when team prefers Chrome-only dev.
Pugh outcome (simplified): Baseline = incumbent record-and-play tool. Alternatives scored on cross-browser support, async handling, CI cost. Winner: code-first framework with explicit wait helpers + grid — higher upfront skill, lower flake and license cost at scale.
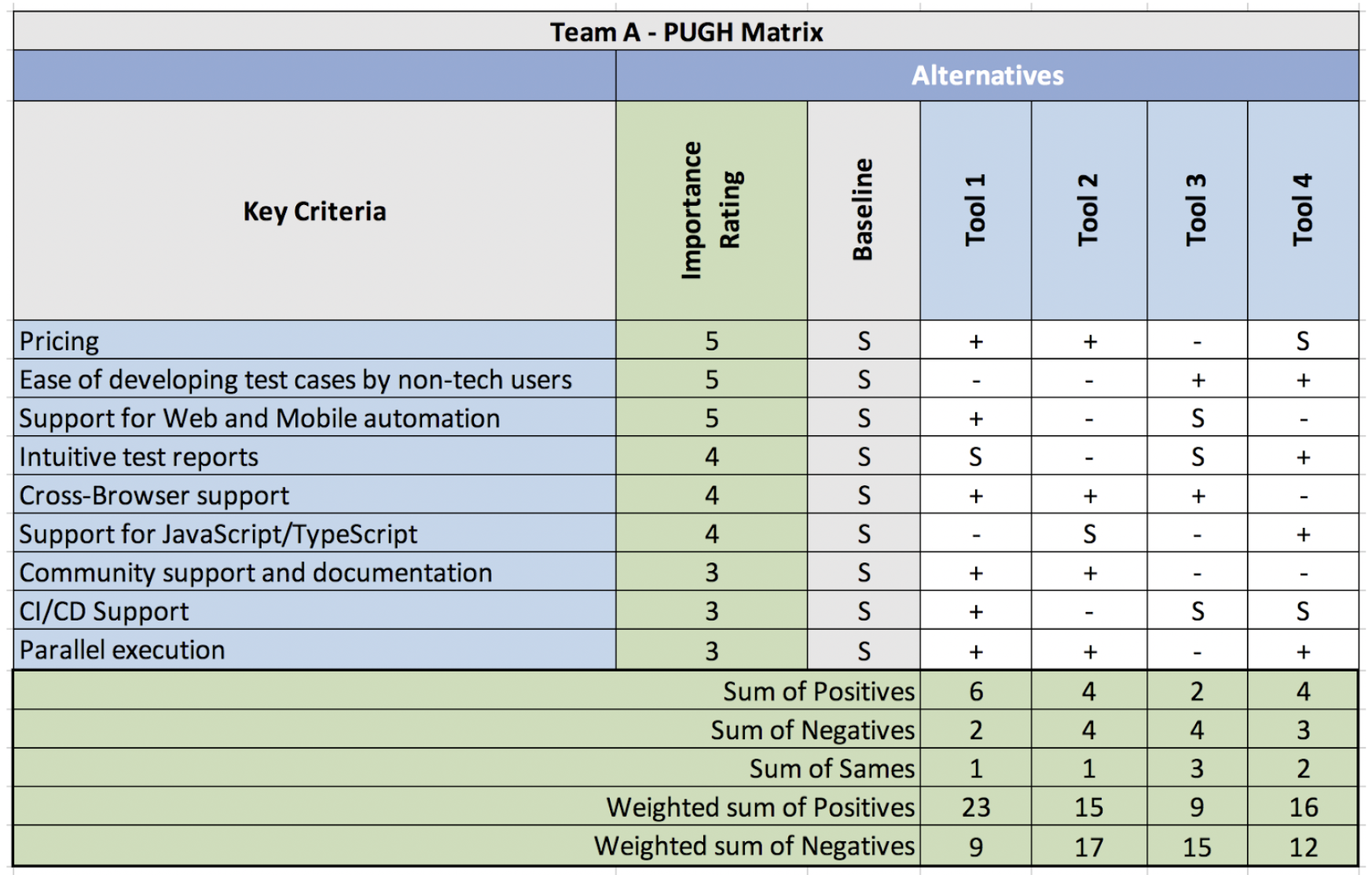
What happened: They accepted slower initial script writing. Devs contributed API tests (pyramid); UI layer stayed thin. Regression time dropped after month three — not week one.
Team B — Java shop, Chrome-heavy, vendor support OK
- Client maintains own tech stack preferences
- Team comfortable with Java and JavaScript
- Mostly in-house Chrome users
- End-user training possible after go-live
- Client comfortable with tool support cost
Pain if they pick wrong: Over-engineering multi-browser grid nobody needs; team avoids automation because “only QA knows Kotlin.”
Pugh outcome: Baseline = manual regression. Winner: commercial tool with strong recorder, Java bindings, vendor support — faster start, annual license accepted.
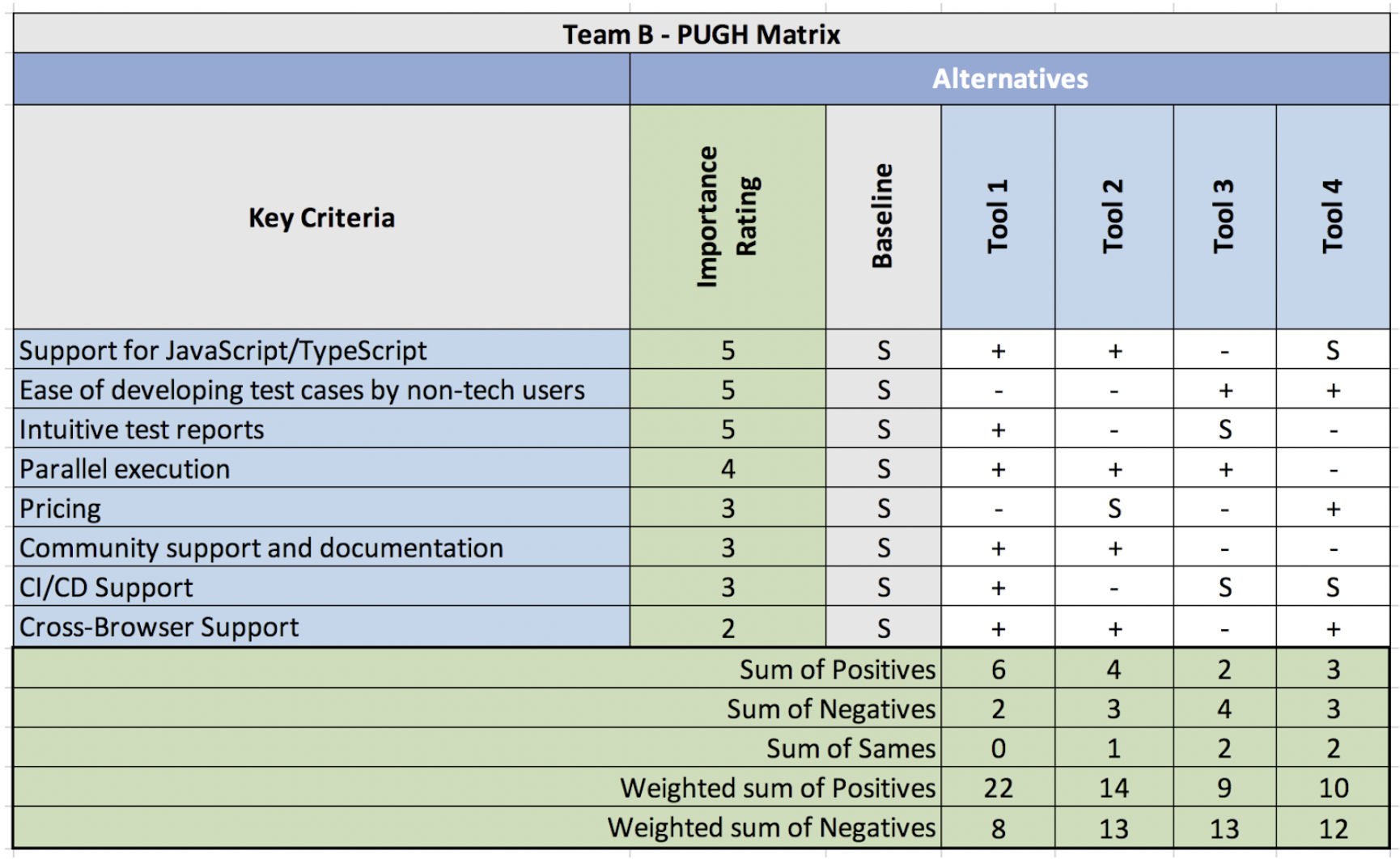
What happened: Record-and-refine got BA and junior QA contributing. They hit limits on complex async flows later — planned spike to hybrid (API layer in RestAssured, UI in same vendor stack). Tool was not forever; it was good enough with upgrade path.
For Pugh steps, see iSixSigma Pugh matrix.
How to run a decision without analysis paralysis
- Criteria workshop — 30 minutes, max eight weighted factors
- Short list — three tools, not twelve
- Spike — one real user journey, two browsers or two OSes, in CI
- Score — Pugh or simple weighted table
- Time box — decide in two weeks; revisit annually, not every sprint
%3btext-align:center%3b%7d%23mermaid-0 .edgeLabel p%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-0 .edgeLabel rect%7bopacity:0.5%3bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bfill:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-0 .labelBkg%7bbackground-color:rgba(232%2c 232%2c 232%2c 0.5)%3b%7d%23mermaid-0 .cluster rect%7bfill:%23ffffde%3bstroke:%23aaaa33%3bstroke-width:1px%3b%7d%23mermaid-0 .cluster text%7bfill:%23333%3b%7d%23mermaid-0 .cluster span%7bcolor:%23333%3b%7d%23mermaid-0 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(80%2c 100%25%2c 96.2745098039%25)%3bborder:1px solid %23aaaa33%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-0 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:%23333%3b%7d%23mermaid-0 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-0 .icon-shape%2c%23mermaid-0 .image-shape%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3btext-align:center%3b%7d%23mermaid-0 .icon-shape p%2c%23mermaid-0 .image-shape p%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bpadding:2px%3b%7d%23mermaid-0 .icon-shape .label rect%2c%23mermaid-0 .image-shape .label rect%7bopacity:0.5%3bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bfill:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-0 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-0 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-0 .node .neo-node%7bstroke:%239370DB%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node rect%2c%23mermaid-0 %5bdata-look='neo'%5d.cluster rect%2c%23mermaid-0 %5bdata-look='neo'%5d.node polygon%7bstroke:%239370DB%3bfilter:drop-shadow(1px 2px 2px rgba(185%2c 185%2c 185%2c 1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node path%7bstroke:%239370DB%3bstroke-width:1px%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node .outer-path%7bfilter:drop-shadow(1px 2px 2px rgba(185%2c 185%2c 185%2c 1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node .neo-line path%7bstroke:%239370DB%3bfilter:none%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node circle%7bstroke:%239370DB%3bfilter:drop-shadow(1px 2px 2px rgba(185%2c 185%2c 185%2c 1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.node circle .state-start%7bfill:black%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.icon-shape .icon%7bfill:%239370DB%3bfilter:drop-shadow(1px 2px 2px rgba(185%2c 185%2c 185%2c 1))%3b%7d%23mermaid-0 %5bdata-look='neo'%5d.icon-shape .icon-neo path%7bstroke:%239370DB%3bfilter:drop-shadow(1px 2px 2px rgba(185%2c 185%2c 185%2c 1))%3b%7d%23mermaid-0 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker id='mermaid-0_flowchart-v2-pointEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 0 L 10 5 L 0 10 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-pointStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='4.5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 5 L 10 10 L 10 0 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-pointEnd-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='11.5' refY='7' markerUnits='userSpaceOnUse' markerWidth='10.5' markerHeight='14' orient='auto'%3e%3cpath d='M 0 0 L 11.5 7 L 0 14 z' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-pointStart-margin' class='marker flowchart-v2' viewBox='0 0 11.5 14' refX='1' refY='7' markerUnits='userSpaceOnUse' markerWidth='11.5' markerHeight='14' orient='auto'%3e%3cpolygon points='0%2c7 11.5%2c14 11.5%2c0' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='11' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-1' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleEnd-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refY='5' refX='12.25' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleStart-margin' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-2' refY='5' markerUnits='userSpaceOnUse' markerWidth='14' markerHeight='14' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 0%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossEnd' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='12' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossStart' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='-1' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossEnd-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='17.7' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossStart-margin' class='marker cross flowchart-v2' viewBox='0 0 15 15' refX='-3.5' refY='7.5' markerUnits='userSpaceOnUse' markerWidth='12' markerHeight='12' orient='auto'%3e%3cpath d='M 1%2c1 L 14%2c14 M 1%2c14 L 14%2c1' class='arrowMarkerPath' style='stroke-width: 2.5%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath d='M187.766%2c35L191.932%2c35C196.099%2c35%2c204.432%2c35%2c212.099%2c35C219.766%2c35%2c226.766%2c35%2c230.266%2c35L233.766%2c35' id='mermaid-0-L_criteria_spike_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_criteria_spike_0' data-points='W3sieCI6MTg3Ljc2NTYyNSwieSI6MzV9LHsieCI6MjEyLjc2NTYyNSwieSI6MzV9LHsieCI6MjM3Ljc2NTYyNSwieSI6MzV9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M477.406%2c35L481.573%2c35C485.74%2c35%2c494.073%2c35%2c501.74%2c35C509.406%2c35%2c516.406%2c35%2c519.906%2c35L523.406%2c35' id='mermaid-0-L_spike_score_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_spike_score_0' data-points='W3sieCI6NDc3LjQwNjI1LCJ5IjozNX0seyJ4Ijo1MDIuNDA2MjUsInkiOjM1fSx7IngiOjUyNy40MDYyNSwieSI6MzV9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M755.516%2c35L759.682%2c35C763.849%2c35%2c772.182%2c35%2c779.849%2c35C787.516%2c35%2c794.516%2c35%2c798.016%2c35L801.516%2c35' id='mermaid-0-L_score_decide_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_score_decide_0' data-points='W3sieCI6NzU1LjUxNTYyNSwieSI6MzV9LHsieCI6NzgwLjUxNTYyNSwieSI6MzV9LHsieCI6ODA1LjUxNTYyNSwieSI6MzV9XQ==' data-look='classic' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_criteria_spike_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_spike_score_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_score_decide_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='mermaid-0-flowchart-criteria-0' data-look='classic' transform='translate(97.8828125%2c 35)'%3e%3crect class='basic label-container' style='' x='-89.8828125' y='-27' width='179.765625' height='54'/%3e%3cg class='label' style='' transform='translate(-59.8828125%2c -12)'%3e%3crect/%3e%3cforeignObject width='119.765625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eWeighted criteria%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-spike-1' data-look='classic' transform='translate(357.5859375%2c 35)'%3e%3crect class='basic label-container' style='' x='-119.8203125' y='-27' width='239.640625' height='54'/%3e%3cg class='label' style='' transform='translate(-89.8203125%2c -12)'%3e%3crect/%3e%3cforeignObject width='179.640625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3e2-week spike on real flow%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-score-2' data-look='classic' transform='translate(641.4609375%2c 35)'%3e%3crect class='basic label-container' style='' x='-114.0546875' y='-27' width='228.109375' height='54'/%3e%3cg class='label' style='' transform='translate(-84.0546875%2c -12)'%3e%3crect/%3e%3cforeignObject width='168.109375' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3ePugh or weighted score%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='mermaid-0-flowchart-decide-3' data-look='classic' transform='translate(921.1171875%2c 35)'%3e%3crect class='basic label-container' style='' x='-115.6015625' y='-27' width='231.203125' height='54'/%3e%3cg class='label' style='' transform='translate(-85.6015625%2c -12)'%3e%3crect/%3e%3cforeignObject width='171.203125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eDecide %2b document why%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cfilter id='mermaid-0-drop-shadow' height='130%25' width='130%25'%3e%3cfeDropShadow dx='4' dy='4' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3cdefs%3e%3cfilter id='mermaid-0-drop-shadow-small' height='150%25' width='150%25'%3e%3cfeDropShadow dx='2' dy='2' stdDeviation='0' flood-opacity='0.06' flood-color='black'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
Document the why — future hires should not relitigate without new facts.
The paradox of choice
More options often mean worse decisions:
- Open-source democratization → many similar tools, subtle differences
- Team preferences and resume-driven development
- Client mandates vs engineer favorites
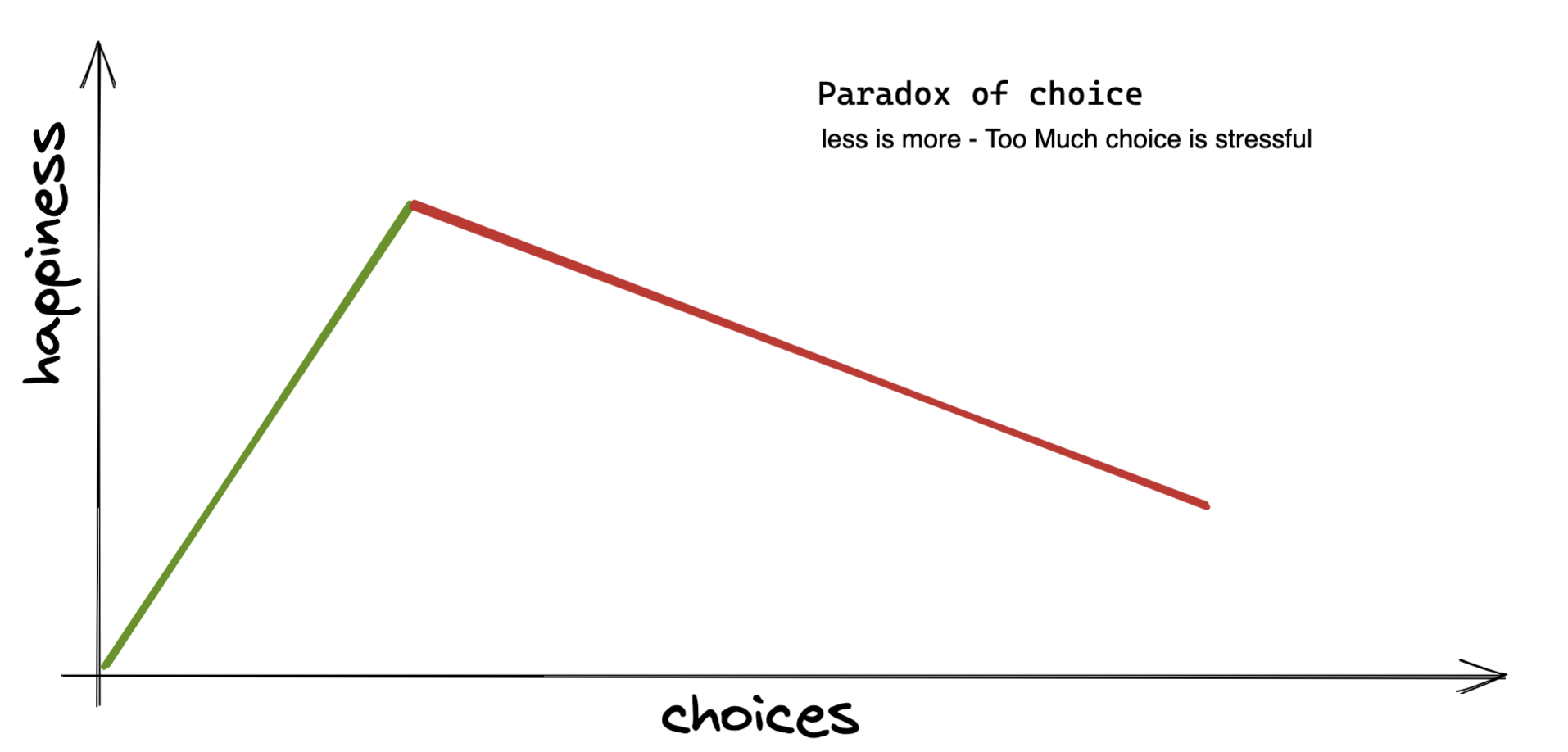
Barry Schwartz was right: after enough alternatives, people delay, second-guess, or buy three tools and use none well.
Antidote for YOUR team:
- Satisfice — pick “good enough on weighted criteria,” not mythical perfect
- Hybrid consciously — recorder for smoke, code for core (who maintains tests?)
- Revisit when constraints change — new mobile app, microservices split (strategy shift)
Red flags during evaluation
- Vendor demo uses apps nothing like yours
- No one ran the spike in your CI
- “We will hire contractors to maintain it”
- Ignores test data and env cost
- Picks tool before strategy
After you choose
- Put ownership in RACI — who fixes broken tests?
- Cap UI count; push logic to API/unit (component strategy)
- Schedule 6-month review: flake rate, maintenance hours, dev participation
Tool selection is a strategy decision wearing a shopping hat. Team A and Team B both chose rationally — their contexts differed.
Which criterion does YOUR team talk about most — and which one (price, maintainability, skills) actually drives the decision?
Happy Testing :)
Comments
Comments are hosted by Disqus. The free tier may show sponsored content.